[EAIS 2020] Emotions Understanding Model from Spoken Language using Deep Neural Networks and Mel-Frequency Cepstral Coefficients

음성으로부터 사람의 감정을 인식하는 문제, Speech Emotion Recognition (SER) 관련 논문입니다.
본 논문의 핵심 아이디어는 CNN 기반 모델을 이용하여 SER 문제를 해결하는 것입니다.
해당 모델은 음성 데이터를 이용하여 8가지 감정을 분류하도록 학습되었고, 최종적으로 0.91의 F1 score 를 얻었습니다.
제안된 모델의 이름은 CNN-MFCC 입니다. MFCC 는 Mel-frequency cepstral coefficients 라는 뜻인데, 이를 단 하나의 입력 feature 로 사용하는 CNN 기반 모델이라 이름이 저렇습니다. 일단 MFCC 가 무엇인지부터 짚고 넘어가겠습니다.
MFCC

해당 논문에서 사용하는 RAVDESS 데이터셋 같은 경우, 오디오 파일이 .wav 로 주어집니다.
- 음성 파일을 짧은 구간 (frame) 으로 나누고,
- 푸리에 변환 (Discrete Fourier Transform) 을 적용하여 주파수 (frequency) 정보를 추출합니다.
3. 위 과정을 모든 frame, 즉, 전체 구간에 적용한 결과가 스펙트럼 (Spectrum) 입니다.
4. Spectrum 에 Mel Filter Bank 를 적용합니다. (Mel Spectrum 생성)
- Mel Filter Bank : 목소리의 주파수 영역대는 자세하게, 다른 영역대는 덜 자세하게 분석하는 필터입니다.
5. Log 를 적용한 후 (Log-Mel Spectrum 생성) 역 푸리에 변환(Inverse Fourier Transform)을 적용합니다.
- (5) 를 Cepstral 분석이라고 하고, 이를 통해 Mel Spectrum 에서 Cepstral 분석으로 추출된, MFCC 가 생성됩니다.
이때 MFCC 는, 주파수 도메인의 정보였던 음성 데이터를, 시간 도메인으로 바꾸었다는 것에 의미가 있다고 합니다.

CNN-MFCC
방금 본 MFCC 가, CNN 모델의 입력으로 쓰이게 됩니다.

각 audio file 로부터 추출된 40개의 features 를 입력으로 사용해서, 8가지의 감정으로 분류하는 네트워크입니다.
입력 features 는 음악 / 오디오 분석에 사용되는 librosa 라는 파이썬 패키지를 이용하여, 각 audio 파일로부터 추출된 MFCC features 를 사용합니다. 이때, features 수는 40으로 지정하였습니다. (40으로 한 이유는 논문에 기술되어 있지 않은데, 라이브러리 docs 를 들어가보니 통상적으로 40을 많이 쓰는 것 같습니다.)
Dataset
Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) 을 사용하였습니다.
파일이름은 03-01-01-01-01-02-05.wav 이런 식인데, 총 7개의 식별자로 구성된 이름입니다.
- Modality (01 = full-AV, 02 = video-only, 03 = audio only);
- Vocal channel (01 = speech, 02 = song);
- Emotion (01 = neutral, 02 = calm, 03 = happy, 04 = sad, 05 = angry, 06 = fearful, 07 = disgust, 08 = surprised);
- Emotional intensity (01 = normal, 02 = strong).
- NOTE: There is no strong intensity for the ’neutral’ emotion;
- Statement (01 = ”Kids are talking by the door”, 02 = ”Dogs are sitting by the door”);
- Repetition (01 = 1st repetition, 02 = 2nd repetition);
- Actor (01 to 24. Odd numbered actors are male, even numbered actors are female).
즉, 모달리티는 오디오+비디오/비디오/오디오 이고, 목소리로 스피치/노래 하고, 감정은 8가지 이고, 감정의 세기는 일반적이거나 강하고, 문장은 2가지 이고, 반복은 두번째까지 있고, 24명의 전문 배우들로부터 얻은 데이터셋입니다.
이때 라벨링은 사람에 의해 직접 제공되었다고 합니다.
CNN 모델은, overfitting 이 생기지 않는다면, 일반적으로 학습 데이터의 양이 많을 수록 학습이 잘 됩니다.
따라서, 데이터셋의 양을 풍부하게 만들기 위해, 디지털 음성/영상 관련 파이썬 라이브러리인 FFMPEG 를 사용해서 비디오로부터 서로 다른 frequency 로 새로운 set of features 를 추출하여 사용하였습니다.
- audio file 는 48MHz 이기 때문에, video 로부터는 44,1Mhz 로 추출하였다고 합니다.
이를 통해, 우리에게 필요했던, ‘noise’ 가 추가되어, 데이터셋의 dimension 을 증가시켜 이용하였습니다.
학습 시, 분류 문제에서 자주 사용되는 Sparse categorical Cross entropy loss 함수를 사용하였고,
평가 성능은 F1-score 로 report 하였습니다.
Results
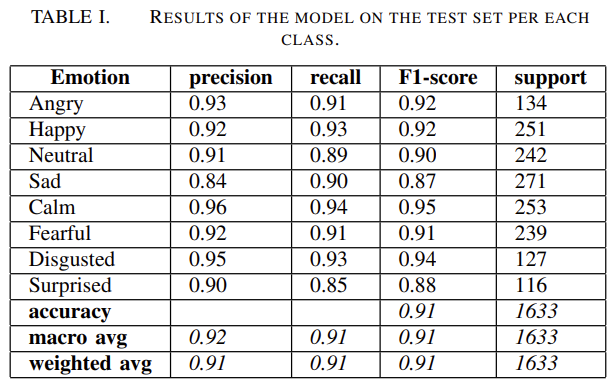
- 이 결과는 precision and recall are very balanced 해서, 거의 모든 classes 에 대해 0.90 근처의 F1 값을 얻을 수 있다는 걸 보여줍니다.
- F1 results 가 별로 차이 안 나는 것은, 모델이 8가지 emotion classes 에 대해 robustness 함을 보여줍니다.
- Sad, Surprised 의 점수가 낮은 데, 이는 speech, facial expression, analysing written text 등에서도 어려운 부분으로 알려져있다고 합니다.
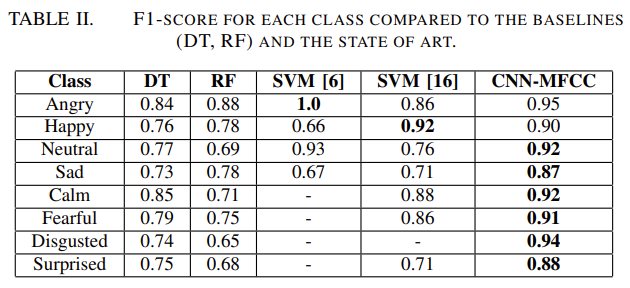
- 해당 모델이 효과적임을 보여주기 위해, 두 개의 베이스라인, decision tree (DT), random forest (RF) 과 다른 논문의 SVM 모델 2개를 가져왔습니다.
- 감정 분류 문제는 classes 의 수가 증가할 수록, 더 어렵고 accuracy 가 떨어진다는 것이 알려져있다고 합니다.
- 그럼에도 불구하고, 제안된 CNN-MFCC 모델은 다른 모델들에 비해 F1 score 가 평균적으로 동등함을 알 수 있었습니다.

- Fig. 2 에서, value of loss (error in the accuracy of the model) 이 test set 과 training set up to the 1000th epoch 에서 decrease 한다는 것을 볼 수 있다.
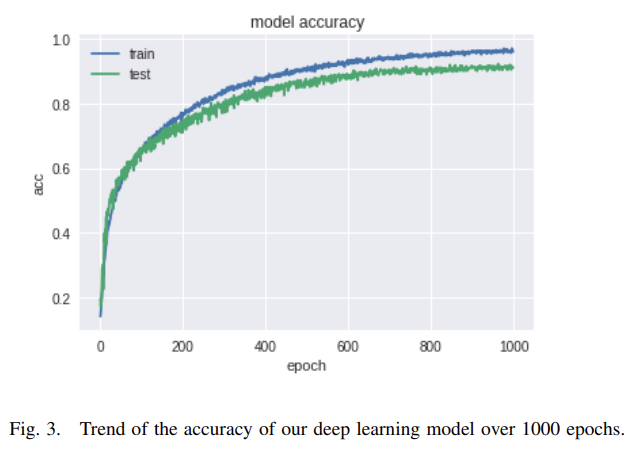
- Fig 3. 에서, avearge value of accuracy on all the classes 가, loss 와는 다르게, ages 가 increases 할 수록 increase 하는 걸 볼 수 있습니다다.
- 이러한 values of loss and accuracy 는 training 과 test dataset 에서 그닥 다르지는 않다. overffiting 되지 않았음을 보여줍니다.
Conclusion
본 연구진은 결과가 고무적이라고 합니다.
- RAVDESS 보다 큰 데이터셋을 사용할 수 있으면, MFCC 는 valid emotion detection feature 가 될 것이고 same model structure 를 사용하면, 노이즈가 있는 상황에서 수집된 데이터셋에 대해서도 비슷하게 수행할 수 있을 것이라고 보입니다.
- MFCC transformation 는 언제나 적용 가능하고, noise reduction 과 enough training data 를 사용하여 잘 작동할 수 있습니다.
- 이에 따라, 본 연구진들은 추후 연구로 실제 사용자들로부터 바로 수집된 대화를 사용해서 실험하는 작업을 하고 있다고합니다.
참고 링크