[AAAI 2021] BSN++ : Complementary Boundary Regressor with Scale-Balanced Relation Modeling for Temporal Action Proposal Generation
바로 이전에, Temporal action proposal 생성하는 BSN (Boundary Sensitive Network)에 대해 리뷰 했었습니다. 이번에 리뷰할 BSN ++ 은, BSN 의 상위 버전인 네트워크라고 생각하면 될 것 같습니다. (저자도 겹칩니다…!) 그렇기 때문에, BSN 에서 있었던 단점을 극복하는 방식으로 3가지의 기여를 했습니다.
기존의 BSN 은 flexible 한 durations 와 reliable 한 confidence scores 를 가진 proposals 를 생성한다는 장점이 있었습니다. 그러나, 3가지 단점이 존재합니다.
- boundary 를 예측할 때, 해당 boudnary 근처의 local deatils 만 사용합니다. 즉, 전체적인 video sequence 에 있는 temporal contexts 를 사용하지 않았습니다.
- confidence 를 평가할 때, proposal 과 proposal 간의 relation 을 고려하지 않았습니다.
- positive/negative proposals 와 temporal durations 의 imbalance data distribution 도 고려하지 않았습니다.
BSN 의 이런 문제들을 해결하는 temporal proposal generation 을 위해, 본 논문에서는 BSN ++ 을 제안합니다. 위에 있는 단점들과 매칭되는, 해결방법들에 대한 간략한 소개입니다.
1. boundary prediction 할 때 rich contexts 를 사용하기 위해, U-shaped architecture 와 nested skip connection 을 사용합니다.
이렇게 하면, 두 개의 최적화된 boundary classifiers 가 ‘같은 목표’ (background → action 이나 action → background 변화를 detect 하는 것 : starting, ending 을 의미) 를 공유하게 돼서, 서로 상호보완을 해줄 수 있습니다. 그리고 이 상태에서, complementary boundary regressor 라는 것을 도입합니다. 왜냐면, input videos 를 역방향으로 가공하면, starting classifer 로 ending locations 를 predict 하는데에도 쓸 수 있기 때문입니다. (그 반대도 마찬가지) 이렇게 하면 추가적인 parameter 없이도 높은 precision 을 달성할 수 있습니다.
2. densely- distributed proposals 의 confidence scores 를 predict 하기 위해, proposal-proposal relation modeling 에서 channel-wise / position-wise global dependencies 를 둘 다 고려하는 a proposal relation block 을 디자인했습니다.
3. sampling postivies / negatives 간의 imbalance scale-distribution 를 완화시키기 위해, IoUbalanced (positive-negative) sampling 과 scale-balanced re-sampling 으로 구성되어 있는 a two-stage re-sampling sheme 를 구현했습니다.
또한 BSN++ 은, boundary map 과 confidence map 이 a unified framework 에서 동시에 생성되고, 결합되어 trained 됩니다. (BSN 은 unified 아님!)
즉, 본 논문에서는 기존 BSN 의 문제들을 해결하는 temporal proposal generation 을 생성할 수 있는, BSN++ 을 제안합니다.
Our Approach
Problem Definition

Video Feature Encoding
BSN++ 을 적용하기 전에, 우선 Two-stream networks 를 사용해서 visual features 를 encode 합니다.

Proposed Network Architecture : BSN++
BSN 은 여러 개의 stages 로 이루어져 있었는데, BSN++ 은 proposal map을 하나의 network 에서 만들어냅니다.

BSN++ 은, boundary information 을 나타내는 boundary map 과, densely distributed proposals 의 confidence scroes 를 나타내는 confidence map 을 생성하도록 디자인 됐습니다. 이때, BSN++ 은 세 개의 modules 로 이루어져 있습니다.
- Base Module : input video featurse 를 이용해서, temproal information modeling 을 수행한다. (output features 가 이후 두 모듈에서 사용된다)
- Complementary Boundary Generator : a nested U-shaped encoder-decoder 를 사용해서, input video features 를 가공해서 boundary probabilities sequence 를 평가한다.
- Proposal Relation Block : 서로 complementary dependencies 가 있는, 두 개의 self-attention modules 를 사용해서, proposal-proposal relations 를 model 한다.
Base module
temporal relation modeling 을 할 수 있는 features 를 extract 하는 모듈입니다. 해당 모듈에는 두 개의 1d convolutional layers (256 filters, kernel size 3, stride 1) + ReLU activation layer 가 있습니다. 이 모듈에서 extracted 된 features 는 이후에 두 모듈의 input 으로 들어갑니다. (이 때, video 의 길이는 정해지지 않았기 때문에, 일련의 sliding windows로 video sequence 를 잘라냅니다)
Complementary Boundary Generator
image segmentation 에서 성공적으로 쓰였던 U-net 에 영감을 받아서 디자인 됐습니다. Encoder-Decoder networks 는 high-level 의 global context 와 low-level 의 local details 를 동시에 잘 포착한다는 특징을 가집니다.

해당 그림 에서, 각 원은 1D convolutional layer ( 512 filters, kernel size 3, stride 1) + batch normalizatoin layer + ReLU layer 를 나타냅니다.
- 두 개의 down-sampling layers 를 추가해서 receptive fields 를 확장시키고, 두 개의 up-sampling layers 를 추가해서 origianl temporal resolution 을 회복 시킨다 → overfitting 방지
- 빨간 점 : deep supervision → fast convergent speed 를 위해 수행됨
- nested skip connections → decoder 와 encode 의 feature maps 을 fusion 하기 전에, semantic gap 을 bridging 하기 위해 적용됨

Proposal Relation Block

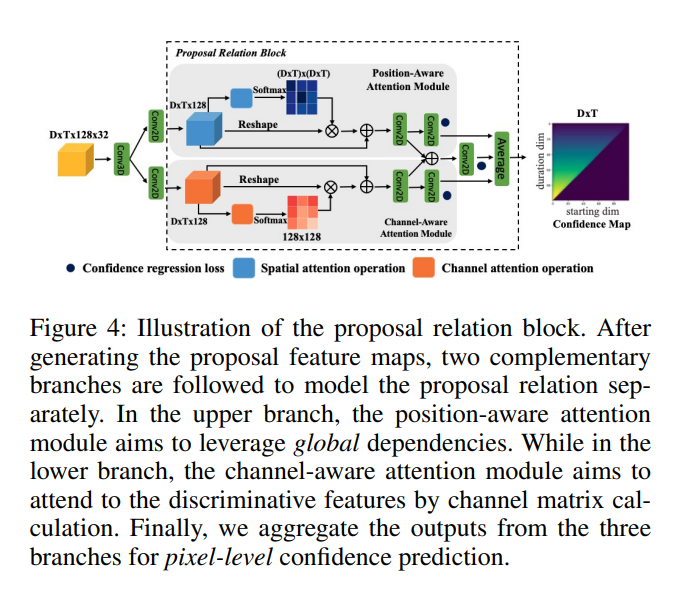

Proposal relation block의 두 attention modules 에서 나온 outputs 를 aggregate 해서, proposal confidence prediction 에 사용합니다. 마지막으로, 더 좋은 성능을 위해, 세 개의 브랜치에서 나온 predicted confidence maps 를 fuse 합니다.
Re-sampling
데이터 분산 불균형이, 특히 long-tailed dataset 에서는, 모델 학습에 악영향을 줄 수 있습니다. 따라서 positive/negative samples distribution 을 고려해서, confidence prediction 의 성능을 향상시키고, proposal-level resampling method 를 디자인해서, long-tailed dataset 에서의 학습 성능을 높이고자 합니다.
해당 논문에서 resampling 전략은 두 개의 stages 로 구성되어 있습니다. 이는 positives / negatives proposals 를 균형있게 하는 것 뿐만 아니라, proposals 의 temporal duration 또한 균형있게 합니다.
IoU sampling

해당 논문의 티저 이미지를 보면, mini-batch loss distirubtion 에서, positives 와 negatives 가 많이 차이 나는 것을 볼 수 있습니다. 이는 training model 을 편향되게 만들 것이기 때문에, 이걸 균형있게 할 수 있는 방법을 고안해야 합니다.
Scaled-balanced re-sampling

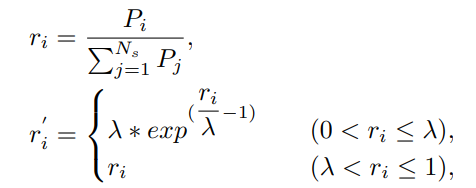

Training and Inference of BSN++
Training : 데이터를 이용해서, weight 를 업데이트 하여 모델을 만드는 과정


Objective of CBG

output probability 와 corresponding label sequence 간의 weighted binary logistic regression loss ��� 를 objective 로 설정했습니다.

Mean-square loss 도 two-passes imtermediate features 에 대해 행해진다.
Objective of PRB.

Score Fusion


Redundant Proposals Suppression.
BSN ++ 이 생성하는 proposal candidate set :

Experiments
Datasets :
ActivityNet-1.3 : action recognition 과 temporal action detection tasks 에 쓰이는 large-scale video datasets. 19,994 개의 비디오, 200 개의 action classes.
THUMOS-14 : untrimmed videos with temporal annotations of 20 action classses.
Implementation details :
feature encoding : two-stream network (ResNet, BN-Incdeption 이 spatial and temporal networks 로 각각 사용됨)

ActivityNet)
(1) input videos 의 feature sequence 를, linear interpolation 을 이용해서, ��=100 로 rescale 함.
(2) maximum duration D = 100 ( 모든 action instances 를 커버하기 위함)
THUMOS14)
(1) input videos 의 feature sequence 를, linear interpolation 을 이용해서, ��=128 로 rescale 함.
(2) maximum duration D = 64 ( 98%의 action instances 를 커버하기 위함)
두 데이터 셋 모두, BSN++ 을 바닥부터 학습시킨다.( optimizer = Adam, batch_size = 6, 초기 7 epoch 동안 lr = 0.001 , 이후 3 epoch 동안 lr = 0.0001)
Temporal Proposal Generation

ActivityNet-1.3 에 대한 결과 비교.
BSN++ 이, sota proposal generation methods 를 큰 차이로 넘겼습니다.
AR : Average Recall
AN : Average Number
AUC : Union under AR vs. AN curve (AN ranges from 0 to 100)

THUMOS14 에 대한 결과 비교.
featurse 는, two-stream featrues 와 C3D featurse 를 사용했습니다.
(1) 어떤 feature 를 사용하든 간에, BSN ++ 이 sota 를 달성했습니다.
(2) Soft-NMS 로 post-processed 됐을 때, 더 적은 수의 proposals 를 사용하여 더 higher 한 AR 을 얻을 수 있었습니다.

Ablation Experiments.
BSN++ 를 ActivityNet-1.3 의 validation set 을 이용하여 평가했습니다.
(1) Encoder-Decoder 구조가, accurate boundary prediction 를 위한 “local to global” context 를 효과적으로 학습했다. (이전의 works 는 local details 만 봤다)
(2) bidirectional matching mechanism 은 boundary 를 판단하는 데 있어서 중요하다는 것이 검증됐다.
(3) proposal relation block 은 accurate 하고 discriminative 한 proposals scoring 을 위한 comprehensive features 를 제공한다. (이전의 works 는 proposals 를 각각 따로 다뤘다.)
(4) scale-blanced sampling → model이 equivalent balancing 을 얻었다.
(5) separated modules 를 end-to-end netowrk 로 합침으로써, 성능 향상이 이뤄졌다.
(6) BSN++ 이 이전의 methods 에 비해, overall efficeinct 하다.
TEM : boundary probabilities sequence generation 에 local details 만 봤었습니다. 그렇지만, temporal context 를 전부 사용하지 않으면, 복잡한 시나리오에서 robust 하지 않게 됩니다. 따라서, BSN은 confidence regression 에서 proposal relations 를 model 하는 것을 실패했습니다. 또한 proposal duration 에 대한 imbalance data distribution 도 무시했습니다. 그러나, BSN++ 은 이러한 이슈들을 잘 다뤘음을 보여줍니다.

Generalizability of proposals :
두 가지 un-overlapped action subsets 를 seen 과 unseen subset 으로 선택했다고 해봅시다. Sports-1M dataset 으로 pre-trained 된 C3D network 로 featur extraction 을 하고, BSN++ 를 seen, seen+unseen training video 로 학습 시켰을 때, 해당 모델들을 validation videos 로 평가해본 결과입니다.
unseen 에서 아주 약간의 drop 만이 있었는데, 이는 BSN++ 이 great generalizability 를 갖고 있음을 뜻합니다. 따라서, unseen actions 에 대해서도 양질의 proposals 를 생성할 수 있음을 보여줍니다.
Action detection with our proposals


ActivityNet-1.3, THUMOS14 에서, BSN++ 이 sota 를 달성했음을 보여줍니다.

결론
temporal action proposal generation 을 위한, BSN++ 을 제안했습니다.
앞서 언급했듯 BSN 의 단점이 3가지 있었는데, 그걸 아래 3가지로 해결합니다.
complementary boundary generator
- U-shaped architecture, bi-directionnal boundary matching mechanism → boundary prediction 을 위한 rich contexts 를 학습
proposal relation block
- confidence evaluation 을 위한, proposal-proposal relations 를 model 하기 위함.
- two self-attention modules → global and inter-dependencies modeling 을 perform 함.
imbalanced data distribution of proposal duration 을 고려
- IoUbalanced (positive-negative) sampling 과 scale-balanced re-sampling 으로 구성되어 있는 a two-stage re-sampling sheme 를 구현
또한 boundary map 과 confidence map 이 하나의 network 에서, 동시에 생성됐고, ActivityNet-1.3 과 THUMOS14 에 대한 실험이 수행함으로써 temporal action proposal / detection 에서 BSN++ 이 sota 라는 것을 보여주었습니다.
논문 링크